am
Lerneinheit drei: Funktion und Aufbau von Bibliothekssystemen 2/2
Koha zum Zweiten
Die Installation war ja quasi ein Kinderspiel. Also machte ich mich kurz vor dem zweiten Teil daran, noch die restlichen Kaptiel des Tutorials von Zefanja durchzuarbeiten.
Da hatte ich zwar in der BAIN-Anleitung gelesen, dass man im Kapitel zwei das bibliografische Framework nicht bearbeiten sollte. Da ging aber wohl der Enthusiasmus mit mir durch und ich machte den Export, zuerst als .csv, dann als .ods, weil die Datei ja ganz offensichtlich zwei Reiter hatte, die auf einem CSV irgendwie nicht so übersichtlich waren.
Also hangelte ich mich durch die Libre-Office-Installation per Kommandozeile, weil das GUI mit einem ladmin-Passwort gesperrt war, und modifizierte fix das Schnellaufnahme-Framework gemäss Tutorial und importierte es wieder ohne jeden Fehler.
Katalogisieren, Ausleihen, Rückgabe – alles easy, wenn das Framework läuft
Alles in Butter also, dachte ich auch dann noch, als unser Dozent erklärte, was dabei alles schieflaufen kann auch ohne Fehlermeldung (wegfallende führende Nullen und so Spässe). Es flog mir erst um die Ohren, als wir als Übung ein Buch per Schnellaufnahme katalogisieren sollten: da war die Schnellaufnahme nämlich gähnend leer. Nix dabei, dachte ich mir, und wollte den unbearbeiteten CSV-Export wieder importieren, was dann allerdings einen Import-Fehler warf. “Wie bitte?” Wozu dann .csv exportieren, wenn genau die Datei nicht mehr zurück kann??
Die Idee zum Fix kam dann vom Dozenten: ein unbearbeiteter .ods-Export einer Kollegin importieren. Super Idee, gut, gibt es Webmail-Accounts, denn das Einbinden eines USB-Sticks in die VM klappte auch nicht … Mit etwas Verspätung konnte ich dann mein Buch ohne Probleme katalogisieren, ausleihen und wieder zurückbuchen. Da war ich aber dann schon nicht unfroh darüber, war eine erfahrene Bibliothekarin in meinem Rücken, die mir in den doch recht unübersichtlichen MARC-Feldern den Weg wies (und das war die stark reduzierte Schnellaufnahme!!). Ich denke ich weiss jetzt, wieso Systembibliothekar’innen die Kommandozeile mögen, mit der sie diese Felder batchweise bearbeiten können. Diese “Erbsenzählerei” beim Katalogisieren ist gar nicht meins!! Falls man das aber richtig machen will, und das Bibliothekssystem Koha heisst, hilft einem diese Bachelor-Arbeit weiter.
Datenimport über Z39.50/SRU
Dann war da noch die Übung mit den Schnittstellen. Wie kann man mit Katalogen von anderen Bibliotheken Arbeit sparen? Man fragt deren Katalogisate über eine Schnittstelle ab! Sowas passt mir natürlich, die ich nicht so gern selber katalogisiere! 😇
Wir richten also in einer Übung gemäss Anleitung eine Schnittstelle zum Z39.50-Server des GBV ein. Das ist eine Verbundzentrale mehrerer deutscher Bundesländer, die eine Suche über alle Kataloge der beteiligten Bibliotheken ermöglicht.
Damit lässt sich jetzt im Modul Katalogisierung eine Abfrage (nach Titel, Autor, ISBN und anderem mehr) über diesen Server absetzen. Da der MARC21 zurückgibt, können wir das Katalogisat in unseren Katalog übernehmen, wir brauchen bloss noch den Medientyp anzugeben und ein Exemplar hinzuzufügen (falls wir tatsächlich eins in der Bibliothek haben).
Ich wollte – mich an die letzte Sitzung und die Metadaten erinnernd – die sru-Schnittstelle zur Swissbib einrichten, scheiterte aber. Zuhause versuchte ich es dann noch einmal, mit den von Sven Meyer recherchierten Tipps und seinen Hinweisen zur Konfiguration der Suchfelder. Immer noch ohne Erfolg; die Schnittstelle spuckte einfach keine Daten aus! Ich folgte also dem Link ins Rabbit hole des Wiki-Eintrags, und nach sehr genauem Lesen offenbarte sich mir endlich der Fehler:
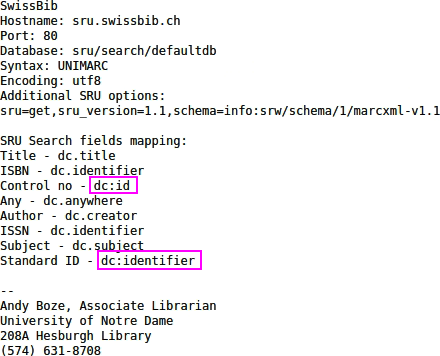
Es müssen doch tatsächlich die ID-Felder mit Doppelpunkt, und nicht mit Punkt geschrieben werden wie der Rest. Verstehen muss man das nicht, denke ich. Aber so funktioniert die Abfrage tatsächlich, und zwar auch mit MARC21. Nicht wie beim tapferen Bibliothekar der Universitätsbibliothek von Notre Dame, der im UNIMARC-Format abgefragt hat.

Der Touchdown Jesus am Eingang der Bibliothek hat seinen Namen verdient
Wie es scheint, ist die Koha-Community gut aufgestellt, mit ausführlichem Wiki, und wenn man dereinst tatsächlich mit Koha arbeiten sollte, könnte man sich hier in die deutsche Mailingliste eintragen.
OAI-PMH: Metadaten-Harvesting mit der grossen Kelle
Nun kann man über die vorhin festgelegten Schnittstellen in Koha nur einzelne Ressourcen abfragen, für Abfragen eines Gesamtkatalogs hat sich OAI-PMH etabliert – das Open Archives Initiative Protocol for Metadata Harvesting (in Alma gibt es aber wohl auch über sru-Schnittstellen diese Möglichkeit). Da befinde ich mich natürlich quasi wieder auf heimischer Erde, da ich bei der Arbeit so einen OAI-Server und das dahinterliegende Programm betreue und mitentwickle. Die Queries habe ich drum zugegebenermassen gar nicht weiter angeschaut und bin in meinem Einbinde-Versuch von sru.swissbib versunken …
Exkurs/Rückblick auf den letzten Teil
Wozu ich gar nicht mehr kam letzte Woche ist die Würdigung von Open Hub, einer Plattform zur Beurteilung der Gesundheit von Open-Source-Projekten, im Link am Beispiel von Koha. Das ist eine sehr wertvolle Sache, da es durchaus schwierig sein kann zu beurteilen, wie aktuell eine Software noch ist und ob da noch genug Maintainer involviert sind, damit die Software weiterentwickelt wird. Das kann sehr informativ sein, falls die Untersuchung von Open Hub nicht allzu lange her ist.
Die Zahlen für Koha sind ziemlich eindrücklich und zeigen deutlich, dass die Community sehr aktiv ist und das Projekt stetig weiterentwickelt:
