am
Lerneinheit eins: Technische Grundlagen
Nicht allzu viel Neues unter der Sonne …
Erwartungsgemäss brachte mir die Einstiegsveranstaltung nicht so viel Erkenntnisgewinn, denn die Linux-/UNIX-shell gehört seit einem Jahr zu meinem täglich Brot.
… aber immerhin: CodiMD und github pages!
Das Format mit der CodiMD-Umgebung finde ich sehr ansprechend und für mich schnell und intuitiv. Auch mit GithubPages habe ich vorher noch nie gearbeitet. Da ich ein grosser Fan von Markdown bin und seit vorletztem Semester meine Präsentationen mit Markdown und remarkjs respektive seinem etwas gestylteren Kollegen remark-it produziere, läuft mir auch das Schreiben in Markdown flüssig von der Hand.
Als Folge einer erkältungsbedingten Selbstisolation hatte ich schon vor der ersten Vorlesung im Skript geschmökert und mir gleich ein schickes Template eingerichtet, um das Lerntagebuch zu schreiben. Dies hatte den angenehmen Nebeneffekt, dass ich durch ein paar initiale Fehlversuche beim Forken auch git – das mich bei der Arbeit und fast allen Modulen seit dem PROG-Modul treu begleitet und unterstützt und das ich auf tiefem Komplexitätslevel einigermassen routiniert bediene – jetzt noch etwas besser verstehe. Die ganze Sache mit branches, dem mergen zwischen remote und origin und den pull-requests war mir nie so ganz klar. Jetzt ging mir da ein Licht auf. Einen wesentlichen Anteil daran hat da auch die Dokumentation auf github, die meiner Meinung nach etwas besser auf Anfänger’innen ohne Programmierhintergrund ausgelegt ist.
Arbeiten mit der Unix-Shell
Dass man beim Zugriff auf Server-Infrastruktur (die vorwiegend auf UNIX oder Linux basiert) immer über eine Shell (von der es neben bash noch etliche andere gibt), war mir klar, dass der Grund aber vor allem die Sicherheit ist, war mir neu. Klar, früher fehlten schlicht die Bandbreite und Ressourcen für eine graphische Oberfläche. Dass das heute trotz der Möglichkeit unterlassen wird, weil so ein Angriffsvektor eliminiert wird, leuchtet mir ein: Wo nichts ist, gibt es auch keine Sicherheitslücken!
Auch wenn ich schon viel Routine mit dem Terminal habe, habe ich mich
über Library
Carpentry sehr gefreut. Diese Ressource war mir
gänzlich unbekannt, und bibliotheksspezifisches IT-Wissen ist für mich
derzeit fast Gold wert, denn natürlich kann man alles googeln und es
gibt Shell-Tutorials wie Sand am Meer. Aber Übungen an der Hand zu
haben, die einem dann die tägliche Arbeit ohne viel
Transfer-Hirnschmalz erleichtern, das ist toll. Auch wenn erst beim
Bash-scripting wirklich relevantes Neues dazu kam, gab es so kleine
Ahas, wie das Hin- und Herspringen zwischen zwei Directories mit cd
-, das ich noch nicht kannte. Auch die reverse search mit Ctrl +
r kannte ich nicht, aber da hat sich bei uns bei der Arbeit der Alias
hgrep für history | grep zu sehr bewährt, als dass ich diese
Gewohnheit wohl ändern werde.
Auch Redirects und Pipes verwende ich bei der Arbeit regelmässig, die
Visualisierung im CodiMD hat mir aber so gut gefallen, dass ich sie
hier noch widergeben möchte:
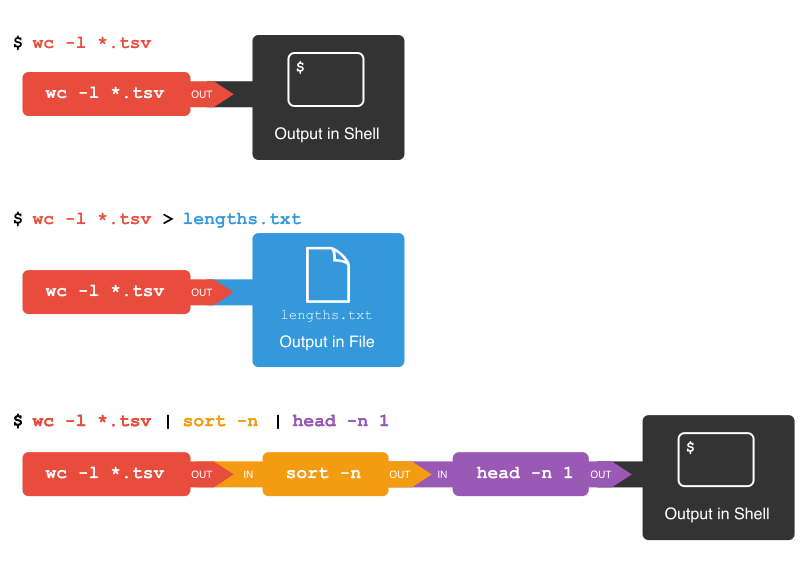 Grundsätzlich: mit einer Pipe kann die Ausgabe eines Programms/Befehls als Input einem nächsten übergeben werden. Mit einem Redirect kann die Ausgabe, anstatt in STDOUT (=das Terminal) beispielsweise in eine Datei geschrieben werden. Mit
Grundsätzlich: mit einer Pipe kann die Ausgabe eines Programms/Befehls als Input einem nächsten übergeben werden. Mit einem Redirect kann die Ausgabe, anstatt in STDOUT (=das Terminal) beispielsweise in eine Datei geschrieben werden. Mit > schreibt man in eine Dati (die erstellt oder überschrieben wird), mit >> hängt man am Ende einer Datei an.
Solche Befehlsketten können beliebig lang werden und am einfachsten baut man sie inkrementell zusammen, wenn man noch nicht sicher ist, ob die Ausgabe auch das liefert, was man erwartet. Ab einem bestimmten Punkt, oder wenn man eine derartige Befehlsverkettung regelmässig verwendet, ist es aber einfacher, dafür ein Shell-Skript zu schreiben, damit habe ich noch keine Erfahrung, weil bis anhin meine Pipes einfach zu kurz sind. Das empfohlene [Bash-Scripting-Tutorial] (https://ryanstutorials.net/bash-scripting-tutorial/) werde ich mir wohl noch genauer ansehen.
Bei der Arbeit verwende ich wc -l auch gerne in Verbindung mit grep, um
beispielsweise records in grossen XML-Dateien zu zählen:
grep -o DATEINAME '<RECORDIDENTIFIER>' | wc -l
Die Option -o gibt jeden Match auf einer eigenen Zeile aus, was
gepipet zum wc -l die Anzahl Records in der Datei zurückgibt.
Ein kleiner Wermutstropfen war für mich, dass “meine” VM keine online-Verbindung zustande brachte; andererseits war das wohl auch für mich am allerleichtesten zu verschmerzen, denn eine Linux-Umgebung hab ich auch auf meiner Arbeits-VM. Ich kann also alle Carpentry-Workshops auch ohne die Horizon-VM machen.
Inzwischen wurde das Problem mit meiner VM behoben; Ursache der Fehlfunktion: der Maschine wurde eine IP zugewiesen, die für Prüfungen reserviert ist und keinen Zugriff auf das Internet hat. 😈
Bleibt mir noch, die Übungen der Lektion 5 zu machen, insbesondere die Regex-Übungen; denn mit den Flavours der Linux-Umgebung tue ich mich immer noch schwer.