am
Lerneinheit sieben: Metadaten modellieren und Schnittstellen nutzen (2/2)
Vom Daten-Rohling zum Metadaten-Diamanten mit OpenRefine
In der heutigen Lerneinheit beschäftigen wir uns mit einer weiteren Möglichkeit, wie wir zu unseren Metadaten in Marc21xml kommen können: Wir modellieren die Metadaten selbst aus Daten, die tabellarisch (bspw. als .csv-Datei) vorliegen. Wir wollen also, in Anlehnung an den Diamanten des Logos, aus einem Rohling einen Diamanten schleifen. Dazu benötigen wir eine Schleifmaschine, und dies ist eben die Software OpenRefine. Unser Schaubild wird entsprechend erweitert:
 Ein weiterer Weg zu passenden Metadaten.
Ein weiterer Weg zu passenden Metadaten.
OpenRefine
Die Software wird zwar lokal installiert, läuft dann aber über eine Browser-Schnittstelle (so wie ArchivesSpace, die Anwendung lauscht einfach auf einem anderen Port, hier 3333).1 Dies scheint der State-of-the-art-Weg zu sein, heutige Software-GUIs zu implementieren; es ist so sicher auch viel einfacher, die Anwendung Plattform-unabhängig zu gestalten.
Zur Einarbeitung vor der Lektion, die heute irgendwie unglaublich schnell wieder vorbei war, haben wir den Workshop zu OpenRefine der Library Carpentry durchgearbeitet.
Wissenswertes über OpenRefine
Der Leitspruch verrät viel über den Metadatenalltag:
“A free, open source, powerful tool for working with messy data”
Leider sind fehlerfreie Metadaten ziemlich seltene Tiere im Bibliothekszoo; oft muss man sich auch mit fremden Metadaten rumschlagen, wofür sich dieses Tool speziell gut eignet. Mit seiner Tabellendarstellung, verbunden mit umfangreichen Analyse, Bereinigungs- und Konvertierungsfunktionalität erlaubt es einem, schnell einen Überblick über auch unbekannte Metadaten zu erhalten.
Mit dem Reconciliation-Tool ist es ausserdem möglich, die Daten zusätzlich anzureichern, bspw. mit Authority-Daten wie VIAF oder Wikidata
Es scheint, als würde der Workshop von Library Carpentry ein Update vertragen.
Dem tabellarischen Aufbau entsprechend eignet sich OpenRefine besonders gut für ebensolche Daten, also CSV, TSV, XLS, XLSX und auch TXT mit Trennzeichen oder festen Spaltenbreiten. Auch flache XML-Hierarchien lassen sich noch bearbeiten. Bei tief verschachtelten Hierarchien wie sie z.B. bei EAD oder LIDO zu finden sind, muss das Tool passen (womit es für mich bei der Arbeit wohl auch ausfällt). In Kombination mit MarcEdit kann es auch für Analyse und Umbau von MARC21 verwendet werden, das haben wir aber (noch?) nicht angeschaut.
Entsprechend wird das Tool offenbar vorwiegend von Bibliothekar’innen verwendet (Peer-Umfrage, evtl. auch ein Bubble-Resultat); für mich persönlich sehe ich als Einsatzgebiet fast nur das Erkunden von noch unbekannten Datenformaten und -Lieferungen.
Besprechung von Fragen aus dem Workshop
Die Schwierigkeiten, die ich mit dem letzten Teil des Workshops hatten, erklärten sich nachträglich damit, dass ich die mit der Facette Stern immer noch bloss die eine Zeile angezeigt hatte, was zur Folge hat, dass das Matching beim Reconciling nicht auf alle Daten läuft. Entweder habe ich übersehen, dass man die Facette wieder löschen soll oder alle einschliessen, oder die Anleitung verdiente eine Präzisierung.
Übung – Templating
In der Übung schliesslich bauen wir uns ein eigenes Template, um von CSV nach MARCXML zu kommen. Wir bekommen eine Vorlage mit einigen bereits umgesetzten Transformationsregeln, die analog wie es in den Spalten auch gemacht werden kann, die Zelleninhalte auswertet und anhand des Templates umbaut. Diese Transformationsregeln sind in GREL verfasst.
Wir sollen zuerst die vorhandenen Einträge analysieren und verstehen, was sie genau tun. Später suchen wir uns dann noch selber in der MARC-Spezifikation Felder, die wir mit den Spaltenüberschriften verwenden und befüllen können.
 Die Templating-Vorlage mit den vorgegebenen ersten Regeln.
Die Templating-Vorlage mit den vorgegebenen ersten Regeln.
Mit GREL, der General Refine Expression Language, können Daten in OpenRefine effizient bearbeitet werden. Die Syntax ist an JavaScript angelehnt, was gelegentlich Überraschungen bringen kann, wenn der Output anders ausfällt als erwartet, wie sich beispielsweise mit slice() offenbart.
slice()mit GREL gibt das Array ab Indexposition bis (ohne) Indexposition zurückslice()mit JavaScript gibt ein Array mit allen angegebenen Indexpositionen zurück
Ein Wermutstropfen der aktuellen OpenRefine-Version ist, dass das Default-JSON-Template wieder geladen wird, wenn man es schliesst zwischendurch (das soll früher anders gewesen sein). Es müssen dann alle Felder wieder befüllt werden (es empfiehlt sich also ein Backup-Textfile!). Dies ist ein üblicher Vorgang, weil leider auch das GREL-Debugging im Template-Fenster nicht funktioniert. Anders in den Transformationen für Zellwerte in Spalten:
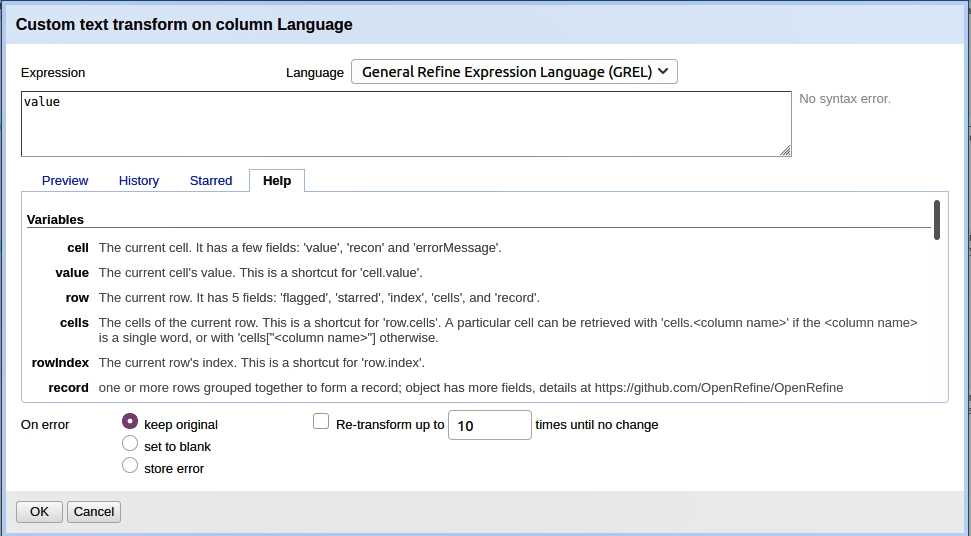 Die Hilfe zu GREL, wie sie bei Transformationen auf Zellen sichtbar ist, auch der Tab preview ist nützlich, dort sieht man gleich, ob das Gewünschte rauskommt.
Die Hilfe zu GREL, wie sie bei Transformationen auf Zellen sichtbar ist, auch der Tab preview ist nützlich, dort sieht man gleich, ob das Gewünschte rauskommt.
Fazit
Es war sehr interessant zu sehen, welche umfangreichen Möglichkeiten die Software bietet, um Daten zu bearbeiten. In der Tat ein sehr mächtiges Tool, zumal man immer gleich sehen kann, wie die Daten dann herauskommen.
Spannend finde ich dabei auch den Gegensatz zur Arbeitsweise bei uns an der ETH-Bibliothek. Soviel ich weiss, benutzen “nur” die Bibliothekar’innen der Katalogisierung ab und an OpenRefine (und MarcEdit). Die Systembibliothekar’innen der Bibliotheks-IT-Services arbeiten – soweit ich das überblicke – mit selbst entwickelten Shell-Skripts und Python-Skript (meist mit dem Pandas-Paket); die Normalisierung für Primo wurde bei Aleph mit Pipes und Drools Tools erreicht (gilt auch für Primo VE in Alma).
-
Ich stelle mir vor, dass dies ein Knackpunkt sein könnte, falls man diverse Software am Laufen hat, die dann gleichzeitig auf demselben Port lauschen will. Das lässt sich aber bestimmt in einer Config-Datei anpassen, wenn nötig. Entweder für OpenRefine, oder dann für die andere Anwwendung. ↩