am
EXKURS: Reconciliation and Templating
GREL kann viel …
… und in phonetischer Anlehnung ans Französische grêle kann einem die Sprache auch gehörig die Laune verhageln. Daran ist sie aber nicht allein schuld; die unverhoffte Zusatzaufgabe hob die Stimmung auch nicht gerade.
Wenn man sich dann aber dran setzt, und sich nach der eigentlich einfachen Reconciliation-Übung mit dem lobid-gnd-Blog 1 anschickt, das jetzt auch noch eins Template einzubauen, dann vermisst man schmerzlich ein vernünftiges Debugging-Feature.
Und wehe der armen Seele, die zu früh Export klickt, ohne das Row-Template kopiert zu haben; sie tippt die mühsam erarbeiteten forNonBlank-Konstrukte (auch vermisst sie die Type-Completion ihrer Python-IDE … 🤬).
Wenigstens ein Workaround für die fehlende Hilfe im Templating kam mir noch in den Sinn: flugs in einem zweiten Tab eine zweite OpenRefine-Instanz starten und dort in der gewünschten Spalte Edit cells > Transform..., und schon hat man parallel Zugriff auf die Hilfe.
Für das 100er-Feld war es ja noch einfach, für die Unterfelder Geburtsjahr und GND-Nummer die forNonBlank-Funktion einzubauen, damit bei den vielen Leeren Zellen nicht tausend leere Elemente gebaut werden.
<datafield tag="100" ind1="0" ind2=" ">
<subfield code="a">{{cells['Authors'].value.split('|')[0].escape('xml')}}</subfield>
{{
forNonBlank(
cells['GND-Nummer'].value,
v,
'<subfield code="0">' + v.escape('xml') + '</subfield>', ''
)
}}
{{
forNonBlank(
cells['Geburtsdatum'].value,
v,
'<subfield code="d">' + v.escape('xml') + '</subfield>', ''
)
}}
</datafield>
Für das 700er-Feld, das ja selber wieder über eine forEach-Schleife befüllt wird; war in nützlicher Frist keine lauffähige Version hinzubekommen. Ich vermute, der Haken liegt darin, dass die Funktion innerhalb des Strings zu liegen kommt, aber auch Backticks, wie sie in Strings für JavaScript verwendet werden können, fruchteten hier nix.
{{
forEach(cells['Authors'].value.split('|').slice(1), v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>
</datafield>')
}}
So viel Einsatz muss für dieses Intermezzo genügen; bin ja dann gespannt auf die Lösung für das 700er-Feld.
Nachtrag
Die Lösung lag tatsächlich darin, dass in der Verschachtelung die inneren geschweiften Klammern entfallen; mein Instinkt die Felder zu Konkatenieren war also doch richtig.
{{
forEachIndex(cells['Authors'].value.split('|').slice(1), i, v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>'
+ forNonBlank(cells['GND-Nummer'].value.split('|').slice(1)[i].replace('$',''), gnd ,'
<subfield code="0">' + gnd.escape('xml') + '</subfield>', '')
+ forNonBlank(cells['Geburtsdatum'].value.split('|').slice(1)[i].replace('$',''), birthdate ,'
<subfield code="d">' + birthdate.escape('xml') + '</subfield>', '')
+ '</datafield>')
}}
Facet for Blank, für True dann Cells > Transform ‘$’. Danach für die Spalten Authors, GND-Nummer und Geburtsdatum wieder Join multivalued cells mit ‘|’ verbinden; dann erst kann man sich ans Templating machen.
”
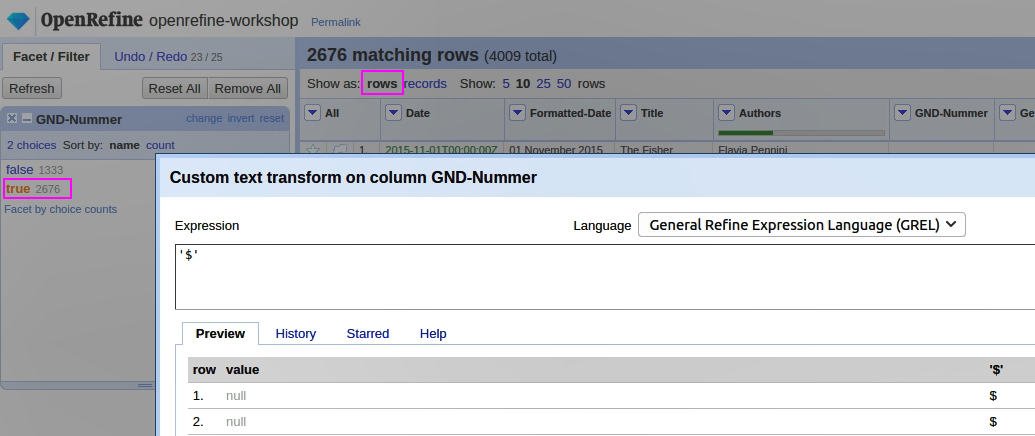
So klappt’s dann auch mit dem sauberen Export 🤓.
-
Davon abgesehen, dass die GND nur ein Drittel der Autoren findet, was dann am Wert der Anreicherung zweifeln lässt. Eine gute Übung und Erfahrung, dass das eben auch nicht nur das Gelbe vom Ei ist, war es allemal. ↩