am
Lerneinheit acht: Suchmaschinen und Discovery-Systeme 1/2
Langer Aufwasch vom letzten Mal, dann geht’s auf Entdeckungsfahrt
In der heutigen Lektion rekapitulieren wir noch die letzte Anreicherungs- und Templatingübung, die die Möglichkeiten und Grenzen von OpenRefine recht schön aufzeigt. Ich habe dazu den Exkurs mit einem Nachtrag ergänzt.
Anschliessend installieren und konfigurieren wir VuFind.
OpenRefine, reloaded
Nachdem alle Templating-Fragen geklärt scheinen, machen wir uns daran, die XML-Daten zu validieren. Dies garantiert einem zumindest, dass die Daten auch dem hinterlegten XML-Schema entsprechen. Dabei können mit Regex auch relativ komplizierte Muster – bspw. für URLs, E-Mails oder ISBN – auf ihre formale Richtigkeit überprüft werden.
Wenn man aber bei der Reconciliation falsche Daten zuweist, nützt die Validierung dann auch nix. Da gilt klar das gigo-Prinzip: garbage in – garbage out!
Prüfen kann man das unter Linux mit dem eingebauten Tool xmllint:
xmllint PATH/TO/FILENAME.xml --noout --schema PATH/TO/SCHEMA.xsd
Die Eingabe überrascht uns mit einer Reihe Fehler: Wir haben doch glatt vergessen, ein Subfield-Element im Template zu schliessen.
 Also nochmal von vorne, und dann klappt das auch:
Also nochmal von vorne, und dann klappt das auch:

XML-Deklarationen
Dazu gibt’s auch noch einen kurzen Exkurs zu den XML-Deklarationen, die wir in unserem Template erstmal einfach weggelassen haben. Sie stehen immer am Anfang einer XML-Datei, das XML kann aber auch ohne validiert werden.
Die Deklaration sagt dem Parser, was für eine Datei jetzt kommt (analog zu HTML-Dateien, die auch eine Deklaration am Anfang haben). Die einzige Pflichtangabe dabei ist version, aber encoding gehört in der Praxis eigentlich auch immer mit. Das optionale Attribut standalone mit Wert “yes” oder “no” zeigt an, ob eine DTD, also eine Document Type Definition enthalten (yes) ist oder referenziert wird (no); falls man es weglässt, setzt der Parser das Attribut selbständig (Default ist yes, ausser, es wird explizit eine DTD referenziert).
Vergleich mit alternativen Tools zu OpenRefine
Als Feedback zu meinem Lerntagebuch-Eintrag werden noch alternative Tools vorgestellt, die anstelle von oder auch in Verbindung mit OpenRefine Anwendung finden. Je nachdem, welche Bearbeitungen man vornimmt und welche anderweitigen Kenntnisse man mitbringt, gibt es Gründe, auch andere Tools zu verwenden, beispielsweise:
- Catmandu (Perl)
- Metafacture (Java)
- MarcEdit (für MARC21, kennen wir ja schon, als Variante evtl. noch pymarc)
Speziell an den ersten beiden Tools ist die eigene Metasprache Fix, die ähnlich wie GREL auch ohne spezifische Perl- oder Java-Kenntisse die Bearbeitung der Daten ermöglichen (ursprünglich aus Catmandu, neu implementiert auch für Metafacture). Schaut man die Tools auf OpenHub an, sind das alles trotzdem eher Orchideen: sie haben eine eher kleine, aber wohl recht enthusiastische Contributor-Basis. Catmandu wurde von unserem Team schon mal ins Auge gefasst; bevor ich dort anfing zu arbeiten, wurde aber der Umstieg auf Python beschlossen wurde, womit sich das dann wohl auch erübrigt (Mental Note: pymarc anschauen).
JSON-Schnittstellen
Dann wurden noch ein paar Worte zu JSON-API-Schnittstellen verloren, die heute State-of-the-art sind und deren Antworten dann eben in JSON zurückkommen statt XML, was moderne Browser auch ziemlich hübsch anzeigen können (die Schnittstelle libd-gnd, die wir mit OpenRefine in der letzten Übung angezapft hatten, gehört da auch dazu).
scrAPIr, das andere Beispiel, sieht aus wie ein Tool, das einen niederschwelligen Zugang zu Api-Schnittstellen bietet, um zu lernen, wie man web scraping betreiben kann. So kann man damit die APIs von grossen Webseiten durchsuchen: Hier kann man beispielsweise auf Stackexchange die letzten 100 Fragen zu Python Data Frames suchen.
Wo ein LIDO ist, gibt’s noch lange keinen Strand
Zu guter Letzt gibt uns dann Sebastian Meyer noch einen rasanten Schnellaufwasch zum Metadatenstandard LIDO (Lightweight Information Describing Objects), der zur Beschreibung von Kulturobjekten vorwiegend von Museen und Kunsthäusern verwendet wird. Da hatte ich mir eigentlich erhofft, evtl. etwas zu lernen, was mich bei meiner Arbeit damit weiterbringen könnte.
Leider erfahre ich da nicht wirklich etwas Neues, aber ich werde immerhin in meiner Erfahrung bestärkt, dass ich da keinen leichten Stand haben werde (es gehört zu meinen Aufgaben, an Crosswalks aus LIDO in andere Formate mitzuarbeiten).
Hellhörig war ich aber zuvor beim Hinweis auf einen bavaricon-Vortrag im Feedback auf Giulias Lerntagebuch geworden. Doch auch dort wurde im Endeffekt am Schluss die Datenbank reverse-engineered, um einen eigenen Export zu bauen :see-no-evil:
Endlich VuFind
Die Aufarbeitung und die Exkurse hatten einige Zeit gekostet; es war aber spannend und lehrreich.
Die Installation von VuFind (und Solr, sowie einer dazugehörigen Datenbank) wurde dann von den Dozenten im Playalong-Stil vorexerziert, wohl weil sie in ihrem Testlauf einigen Fallstricken begegnet waren, die sie uns ersparen wollten:
Es wurde noch einmal erwähnt, weswegen üblicherweise pro Software ein Server verwendet wird: Dependency hell lässt grüssen. Zu gross ist die Gefahr, dass sich verschiedene Systeme nicht vertragen oder eben gar sich ausschliessende Abhängigkeiten haben. Durch Containerisierung (Stichworte: Docker/Podman, Kubernetes, OpenShift)1 können heute diese Probleme umgangen werden und viele Ressource gespart werden, aber das ist eine andere Geschichte.
Auf unserem Ubuntu 20.04 vertragen sich interessantweise alle von uns verwendeten Systeme, allerdings stellt sich bei VuFind ein Hindernis in den Weg, das schon bei ArchivesSpace Melanie und mich ausgebremst hatte: Dieses Tool kann (noch) nicht mit der neusten Java-Installation, weswegen dann Solr nicht starten kann.
Ohne Anleitung durch unsere Dozenten müssten wir uns an dieser Anleitung für Ubuntu orientieren. Daraus haben sie aber die wichtigsten Verzweigungen und Fallstricke festgehalten.
Dabei kommt das eigentlich für flüssiges Abarbeiten vorbereitete Skript ins Stocken, weil diese in einem Block angegebenen Shell-Befehle einzeln hätten ausgeführt werden sollen:
sudo apt install -y openjdk-8-jdk
sudo update-alternatives --set java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
sudo rm /usr/lib/jvm/default-java
sudo ln -s /usr/lib/jvm/java-8-openjdk-amd64 /usr/lib/jvm/default-java
Aber ich greife vor: zuerst galt es, über dpkg, eine Alternative zu apt oder apt-get, die VuFind-Debian-Pakete zu installieren. Doch auch das wirft einen Fehler:
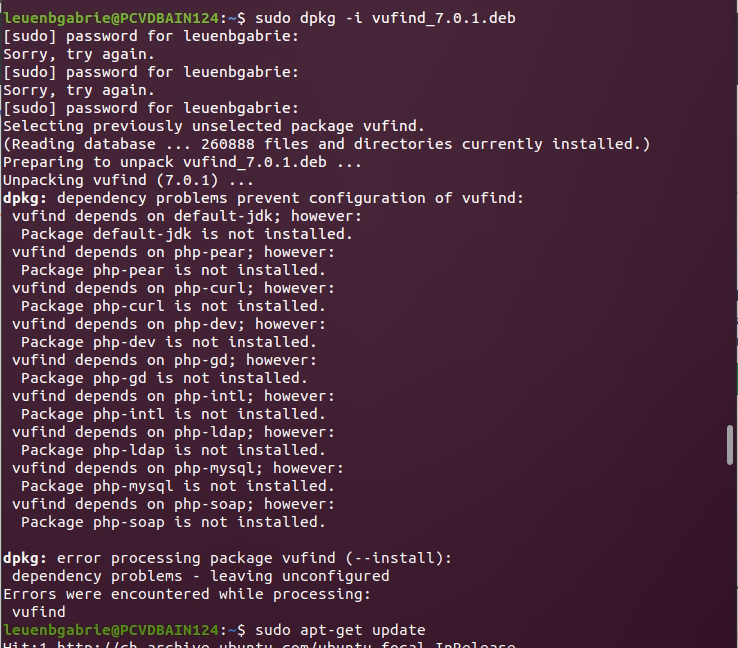
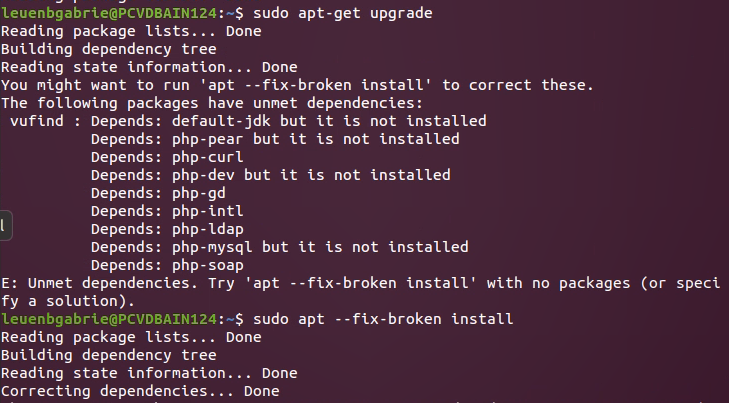
Also zuerst noch mit sudo apt-get update die Paketquellen aktualisieren und (optional sudo apt-get upgrade gleich updaten), sowie sudo apt --fix-broken install die fehlenden Pakete nachinstallieren:
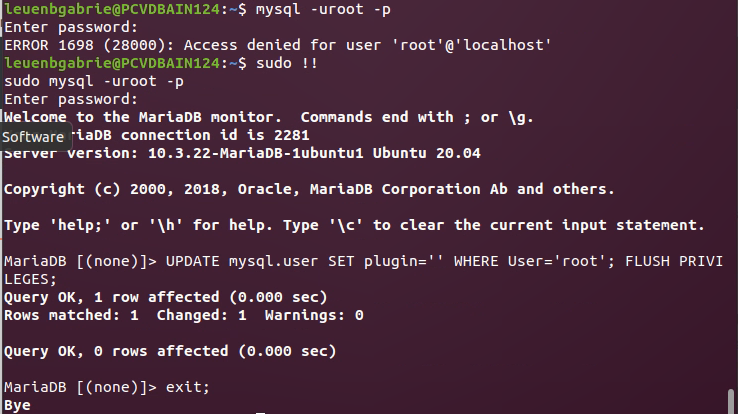
Dann die Datenbank (auf Ubuntu 20.04 MariaDB, äquivalent zu MySql) mit sudo /usr/bin/mysql_secure_installation aufsetzen (enter, root pwd setzen, durch den Rest durchklicken mit enter) und einrichten:
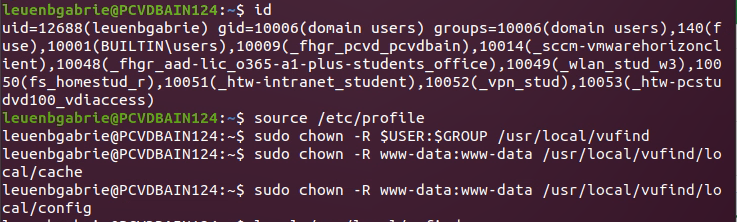
und entgegen der Anleitung mit chown von einigen Dateien die Rechte anpassen, also den Owner changen:
Danach, wenn die richtige Java-Version aktiv ist, startet Solr ohne Mucken:
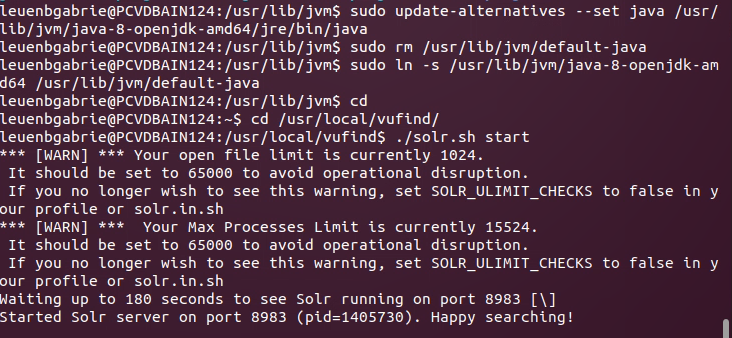
Auch VuFind läuft im Browser und muss noch gemäss Anleitung fertig konfiguriert werden, und mit dem Laden von ersten Testimporten ist auch dieses Modul bereits zu Ende.
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/journals.mrc
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/geo.mrc
/usr/local/vufind/import-marc.sh /usr/local/vufind/tests/data/authoritybibs.mrc