am
Lerneinheit neun: Suchmaschinen und Discovery-Systeme 2/2
Wer sucht, der findet
Und zwar mit einem Discoverysystem wie VuFind; zumindest, wenn die Suchmaschine darunter (in diesem Falle Solr) richtig konfiguriert ist. VuFind hat da umfangreiche Möglichkeiten, wie das Video, das wir als Hausaufgabe angeschaut hatten auf heute, eindrücklich demonstriert. Mir gefällt beispielsweise am searches.ini, wo das Verhalten und auch die Anzeige der Weboberfläche eingestellt werden kann, dass die verschiedenen Handler zumeist alle schon da sind (auskommentiert) und die Optionen ausführlich kommentiert sind. So kann auch später nachjustiert werden, wenn sich im Betrieb herausstellt, dass für die Usability der Nutzenden eine andere Anzeige besser wäre.
Allerdings hatte ich beim Nachvollziehen des Video-Tutorials ein Problem: ich konnte nicht wie vorgeführt das searches.ini in ein lokales config-Verzeichnis kopieren:

Hmm… mit sudo ginge das, aber dann gehört die kopierte Datei root und kann auch wieder nicht mit Sublime bearbeitet werden. Mein Verdacht, dass wegen der Manipulation der Datei-Owner für unsere Installation das Verhalten anders war, wurde mir dann von den Dozenten bestätigt (inklusive dem Hintergrund, dass dieses Verhalten mit dem Aufbau der virtuellen PCs für diesen Kurs zu tun hat, weswegen die UIDs der User und die GIDs der Gruppen nicht in den üblichen Grössenordnungen daherkommen1). Allerdings ist es das Verzeichnis /usr/local/vufind/local/config das nicht den richtigen Owner hatte, weswegen darin keine Datei geschrieben werden konnte.
Entgegen meiner Befürchtung kann ich jetzt hinterher bestätigen, dass die Anpassung für die lokalen configs das Verhalten von VuFind nicht beeinträchtigen. Zusätzlich zu den anderen chown-Befehlen also noch sudo chown -R $USER:$GROUP /usr/local/vufind/local/config eingeben, dann können wie vom Tutorial angegeben das searches.ini und das facet.ini auch bearbeitet werden. Auch mit der Gewichtung der Suchfelder kann gespielt werden (und die korrekten Einstellungen scheinen unter Fachleuten ein grosser Streitpunkt zu sein – logisch, sie beeinflussen ja massgeblich die Resultatsliste), und wäre das dann das searchspecs.yaml:
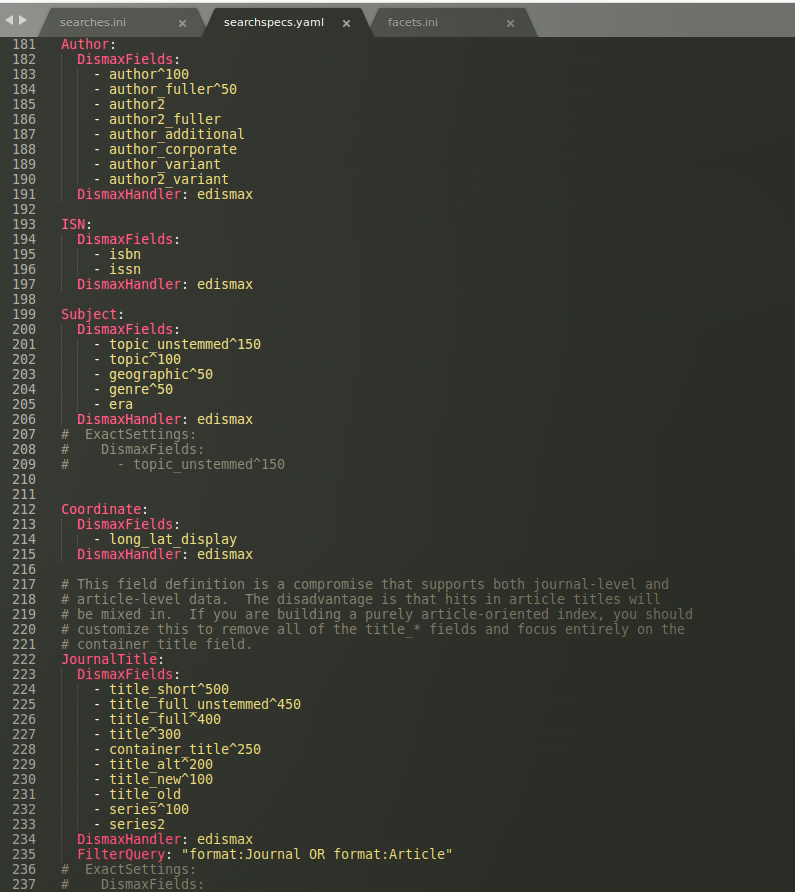 Das Einstellen der Gewichtung geht übrigens überraschend simpel: mit
Das Einstellen der Gewichtung geht übrigens überraschend simpel: mit ^100 wird das Feld mit einem Faktor multipliziert2.
In der Übung schauen wir uns dann aber den direkten Vergleich zwischen einer Suche mit Solr (also der eigentlichen Suchmaschine) und dem Discoverysystem VuFind an. Es wird schnell klar, wieso man da noch eine Schicht drauf gebaut hat:
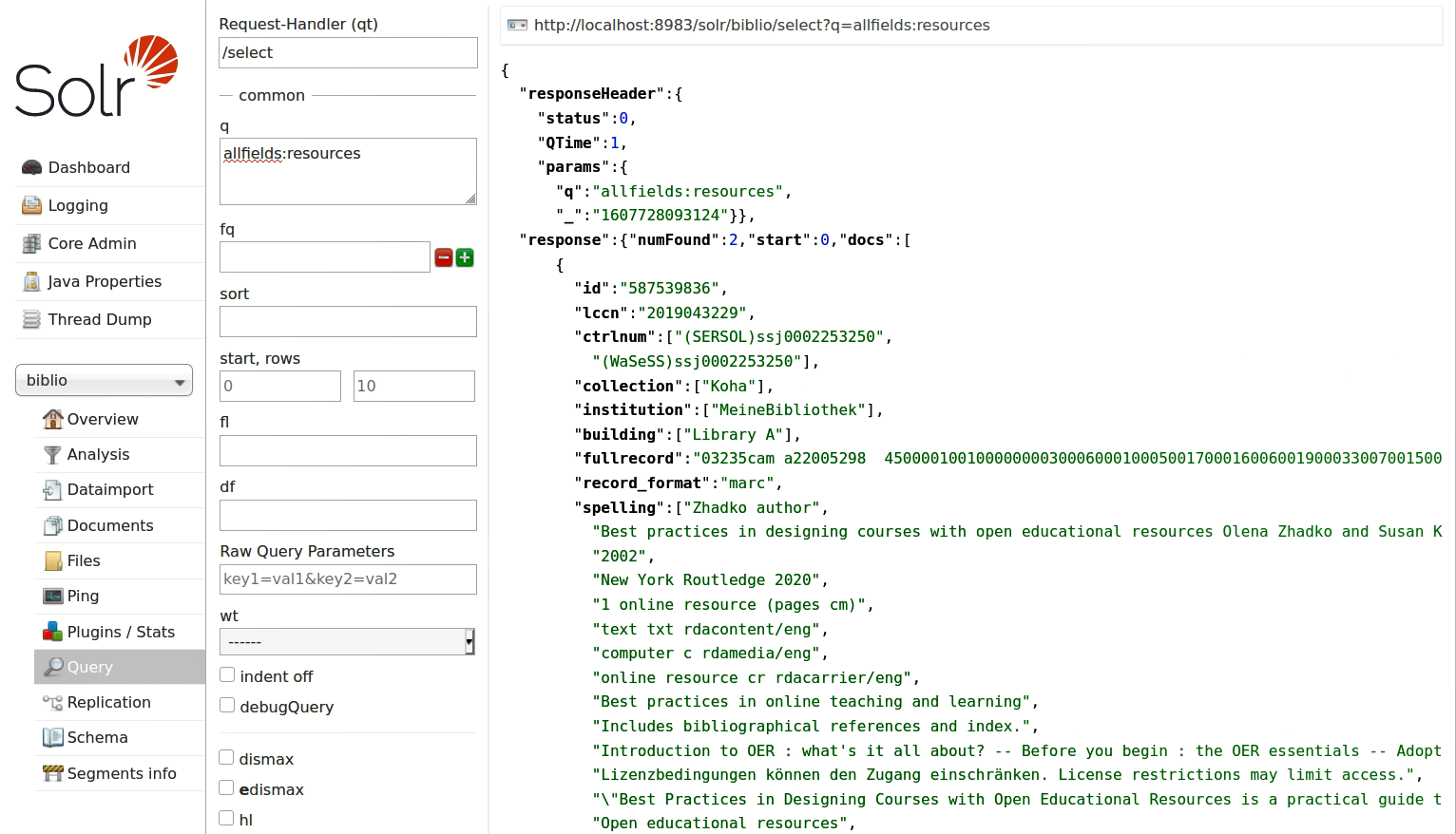 Eine Abfrage in Solr.
Eine Abfrage in Solr.
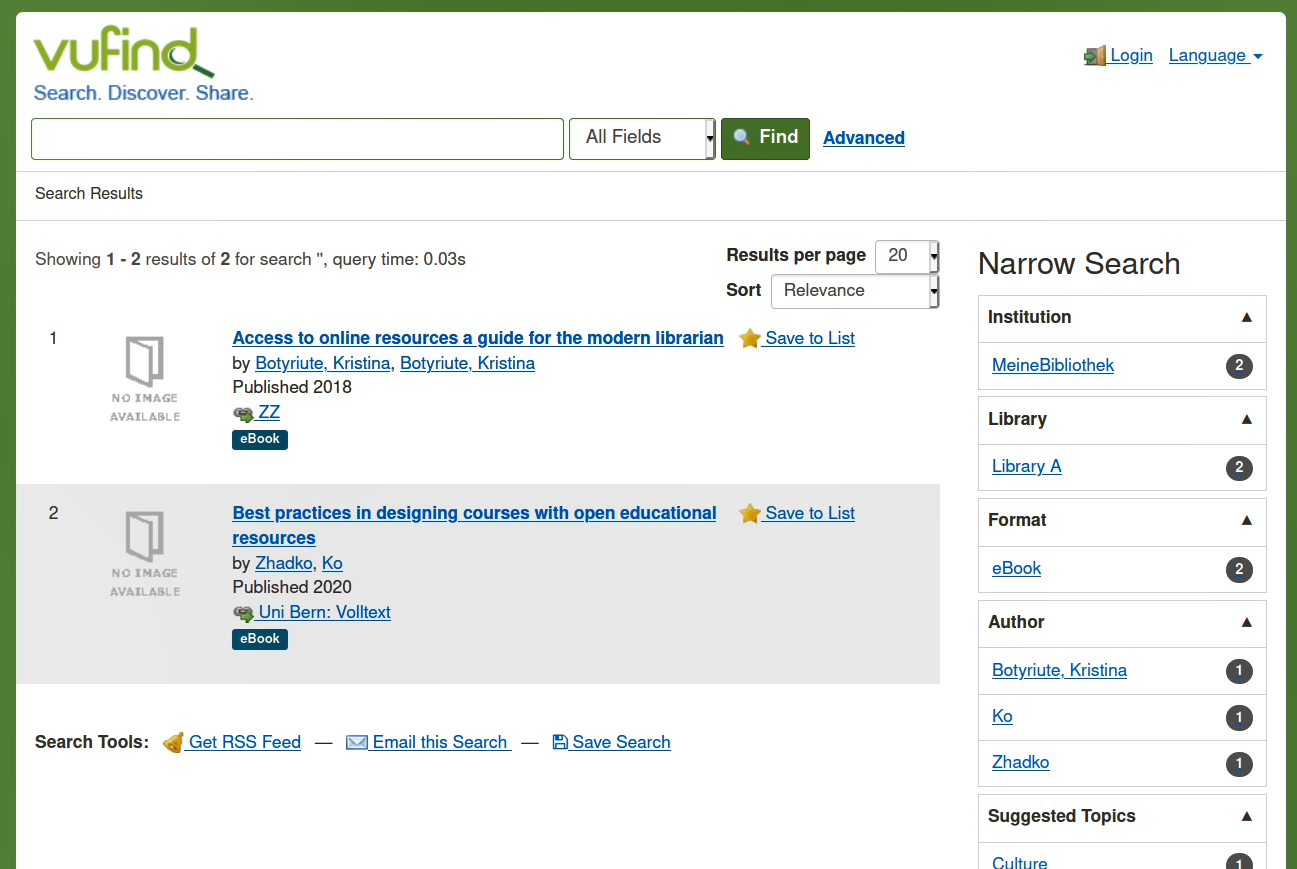 Dieselbe Query in VuFind.
Dieselbe Query in VuFind.
Im Ergebnis hier zwar dasselbe (es sind aber auch nur die zwei Dokumente in der DB, für diesen Screenshot, weil die Testdaten für die zweite Übung schon entfernt wurden), und ja, man kann alles, was VuFind an Suchkonfigurationen mitbringt, auch in der Adminoberfläche von Solr für die Suche eingeben (all die Felder und Checkboxen, die man ticken kann, zeugen davon). Aber wer möchte das schon jedes mal von neuem einstellen für eine Suche?
Den Unterschied sieht man deutlich im Logfile, das Solr für die Anfragen schreibt:
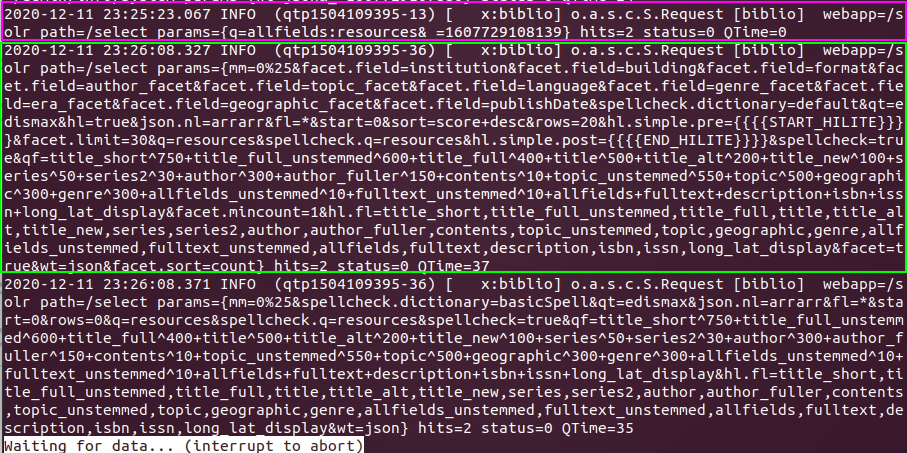 Pink die Zeile für die in Solr gemachte Abfrage (ohne spezielle Tweaks), grün die Parameter, die mit der VuFind-Query an Solr weitergereicht werden.
Pink die Zeile für die in Solr gemachte Abfrage (ohne spezielle Tweaks), grün die Parameter, die mit der VuFind-Query an Solr weitergereicht werden.
Die Gewichtung der einzelnen Suchfelder, die Sortierung der Ausgabe, aber auch die Facetten and whatnot ist alles voreingestellt, in den diversen Konfigurationsdateien von VuFind (eben die, die oben angeführt wurden).
Import-Übung
Wir sollen aber noch unsere selbst produzierten Daten (resp. die Beispieldaten aus den letzten Lerneinheiten) im Sinne der Datenintegration, wie sie ja am Ende unseres hübschen Schaubildes geschehen soll, damit sie anschliessend über die Suche im Discoverysystem zugänglich sind.
Dazu verwenden wir ja Daten im MARCXML-Format, entsprechend müssen wir pro Import die Datei marc_local.properties im Verzeichnis /usr/local/vufind/import anpassen (v.a. collection und institution).3
So weit so gut, doch die Importe mit ArchivesSpace und dspace scheitern, weil ihnen das MARC-Feld 001 als id als unique key zugewiesen ist, das in in MARCXML nicht mandatory ist (validiert also). Der Fehler:
ERROR [SolrUpdate-null-null] (Indexer.java:455) - Failed on single doc with id : null
ERROR [SolrUpdate-null-null] (Indexer.java:465) - Error from server at http://localhost:8983/solr/biblio: Document is missing mandatory uniqueKey field: id
Tatsächlich ist dieses Feld bei den ArchivesSpace- und den DSpace-Daten leer geblieben. Eine Lösung wäre die Überarbeitung der Daten in OpenRefine mit der Vergabe einer hochzählenden ID mit Collection-Spezifischen Prefix. Eine andere Variante wäre es, ein anderes Feld zu wählen für die ID zu wählen, solange man eins findet, das uniqe ist. Wünschenswert wäre aus meiner Sicht auch eine automatische id-Vergabe durch SOLR; dies bringt aber neue Problme (Stichwort Dubletten) mit sich, die ich hier nicht mehr weiter vertiefe.
Zum Schluss diskutieren wir noch kurz über den “perfekten” Katalog, wo nicht ganz überraschend die Meinungen weit auseinander gehen.
Nachtrag vom 18. Dezember
Ein grosser Mehrwert von Discoverysystemen wurde bisher zu wenig erwähnt: der Central Index. Das verbesserte e-Ressourcenmanagement von Aleph-Nachfolge-Systemen ermöglicht einen neuen Zugang zu elektronischen Ressourcen (mit zuschaltbaren Paketen). Hier bringt ein Central Discovery Index, wie er für Primo VE in SLSP verwendet wird (heisst da Primo Central) grosse Vorteile, denn damit wird ein Suchzugriff auf alle verfügbaren elektronischen Ressourcen möglich, ohne dass die Ressource von jeder Bibliothek katalogisiert werden müssen (heute gar nicht mehr leistbar). Solche Index-Datenbanken werden meist aus der Crossref-Datenbank (wo DOIs registriert werden) abgezogen und aus grossen kommerziellen DBs wie EBSCO Discovery Service eingekauft. Im dt. Sprachraum gäbe es für solche Central Indexes bspw. für VuFind bei finc und K10plus; Volltextzugriff ist dann natürlich lizenzabhängig, kann aber separat eingekauft werden.
-
Das riecht mir stark nach Containern für die einzelnen Linux-Installationen; Ähnliches ist mir bei Podman mit seinen rootless usern im Container der Fall, was hier natürlich viel zu tief in ins Container-Rabbit-hole führt, den Link will ich aber trotzdem nicht unterschlagen, auch wenn ich ihn in der Fussnote nicht in ein Label packen kann. ↩
-
Da steigen dumpfe Erinnerungen an das Fach Information Retrieval und die Vektorberechnung beim Vergleich der Suchterme auf. Da war doch was … ob das DisMax etwas mit der maximalen Distanz zu tun hat? Falsch gedacht: es ist der DisjunctioMaxQueryParser (Oliver Pohl, S. 20). So oder so ist klar, dass dann mit einem Multiplikator leicht Gewichte verschoben werden. ↩
-
Gemäss Felix Lohmeier kann man in VuFind Daten im Format MARC21, MARCXML oder XML importieren; für XML-Daten benötigt man aber entsprechende XSLT-Dateien. ↩