am
Lerneinheit zehn: Linked Data
Die letzte Sitzung war noch einmal ein Aufwasch zu Discoverysystemen , insbesondere zur Wichtigkeit eines Central Index (als Nachtrag hier).
Es galt dann, aus verschiedenen Bereichen für einen Praxisbericht auszuwählen; der Bericht über das Literaturarchiv Marbach war dann auch sehr interessant.
Davor gaben uns auf Anregung von Karin Sandra und Alex noch einen spannenden Einblick in Alma nach ihrer ersten Woche SLSP. Erster Eindruck: Klickwege sind nicht wirklich kürzer geworden. Seitenladezeiten sind ein Thema (oft ein Ärgernis). Von den Dozenten wird Alma aber trotz vielen politischen Einwänden ausdrücklich für die vorbildlich programmierten Schnittstellen gelobt.
Aktuelle Datenmodelle: BIBFRAME und RiC
Als letztes theoretisches Thema sprechen wir noch über aktuelle Datenmodelle für Metadaten. BIBRAME für Bibliotheken und RiC für Archive scheinen sich langsam durchzusetzen. Zu RiC habe ich an anderer Stelle schon kurz geschrieben, weswegen ich nur auf BIBFRAME eingehe.1 Als zusammenfassende Einschätzung lässt sich festhalten: in Archiven wird sich die Arbeitsweise durch neue Möglichkeiten der mehrfachen Beziehungen grundsätzlich ändern, und es wird eine stärkere Harmonisierung der verschiedenen Sparten Archive/Bibliotheken geben. Der Einsatz der GND in Archiven hilft da sicher weiter.
Schweizer Versuche zu Archival Linked Opend Data findet man unter http://www.alod.ch (mit Beteiligung: Niklaus Stettler).
Der Standard wird seit 2012 als Nachfolger von MARC21 entwickelt (aktuell BIBFRAME 2.0, seit 2016) und beruht auf den Functional Requirements for Bibliographic Records (FRBR)2 und den Katalogisierungsregeln von RDA (nicht vollständig umgesetzt, sondern vereinfacht diese) und folgt Linked-Data-Paradigmen, was bibliographische Daten endlich Semantic-Web-fähig machen würde. Also: eindeutige URIs, eindeutiges Vokabular und Entitäten nur einmal beschrieben und mit Ressourcen verknüpft durch Relationen.
BIBRAME baut auf auf Model und Vocabulary, wobei das Modell drei Entitäten (Agent, Subject & Event) definiert und zwischen den Ebenen Work, Instance und Item unterscheidet (Work und Expression von FRBR in Work zusammengefasst, Manifestation heisst Instance). Das Vokabular definiert dann Konzepte und Eigenschaften zur Beschreibung der Entitäten im Modell.
 Quelle: https://www.loc.gov/bibframe/docs/bibframe2-model.html
Quelle: https://www.loc.gov/bibframe/docs/bibframe2-model.html
Das steckt noch in den Anfängen, ist aber schon ziemlich gut. Hier gibt es eine Übersicht über Pilotprojekte. Zu Alma steht dort unter Status:
“All bibliographic records in Alma can be viewed and exported as BIBFRAME and can be accessed via a unique URI.”
Hier gibt es Informationen zum Prototyp der Deutschen Nationalbibliothek, und hier eine Gegenüberstellung von MARC21 und BIBFRAME.
Toller Einblick von Sandra und Alex zur ersten Woche Alma-Betrieb mit SLSP.
Praxisberichte
Zum Schluss zeigen uns die Dozenten noch ein Integrationsprojekt, an dem sie derzeit arbeiten (Konzeption und Datenintegration).
Das Marbacher Literatur-Archiv sind eigentlich drei Institute in einem: eine Bibliothek, ein Archiv und ein Museum an einem Ort in unterschiedlichen Gebäuden. ADIS war end of life und old school (ein zwanzig jähriges Bibliothekssystem, basierend auf SQL und relationalen DB). Jede Abteilung hatte eigene Erschliessungstradtionen, trotz gleicher Software (verschieden erfasst und mit unterschiedlichen Metadaten und Sucheinstiegen für Benutzer’innen) Der alte Katalog war der in aDIS/BMS integrierte OPAC, ja. Hier kann der alte Katalog noch ausprobiert werden: https://www.dla-marbach.de/katalog/
Das neue System, das uns von den Dozenten auf der Testoberfläche vorgeführt wird, kann über alles suchen, man kann aber auch wie vorher einschränken. Zusammengeführt wurden die drei Datenbestände in OpenRefine, in einem einfachen CSV-Format.
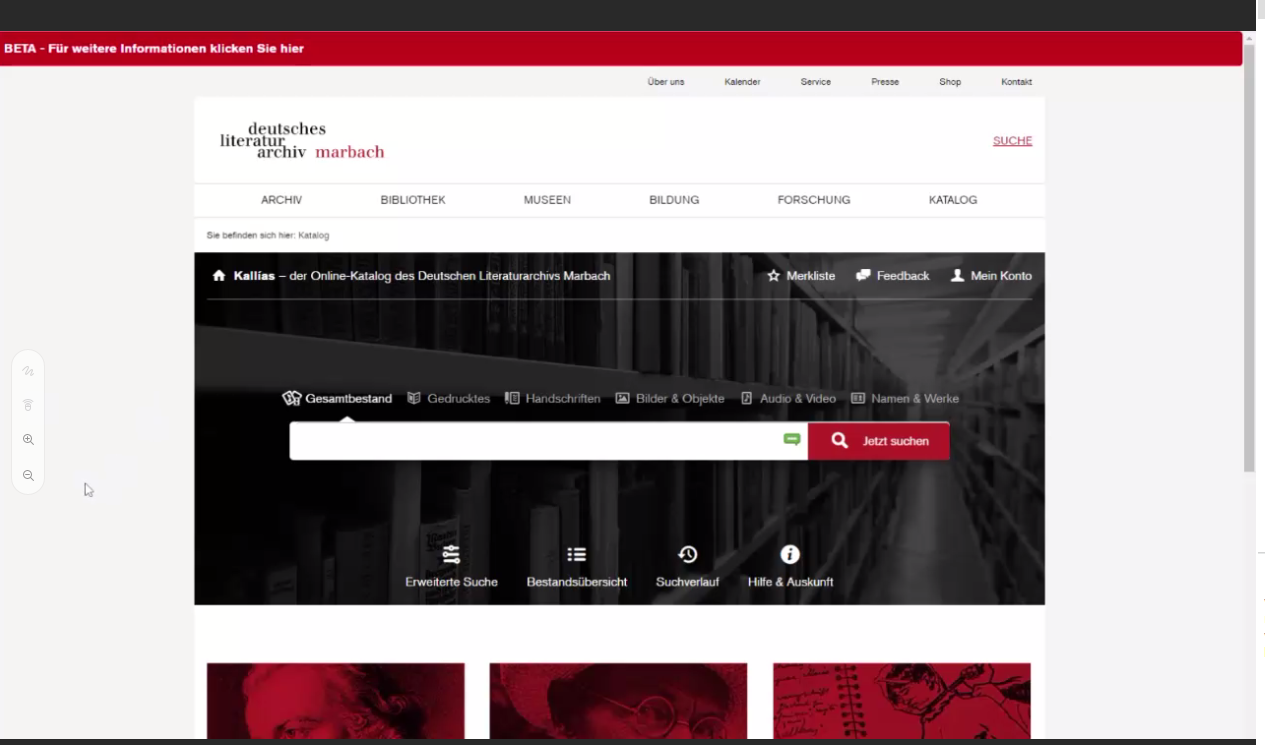
Suche auch nach Normdaten, die relevante Bestände zusammenfassen.
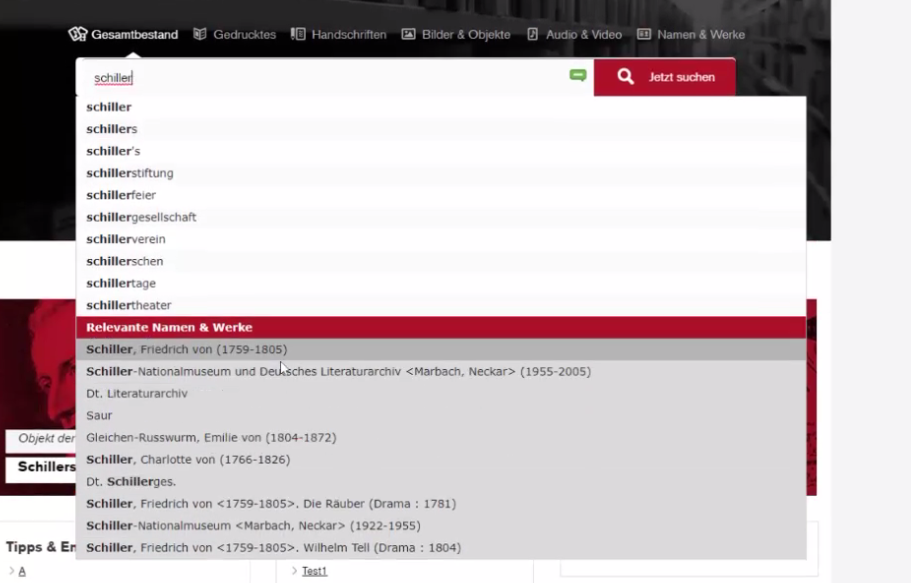
In den Treffern viele Facetten, ähnlich wie in VuFind, mit den Normdaten-Treffern on Top als Besonderheit
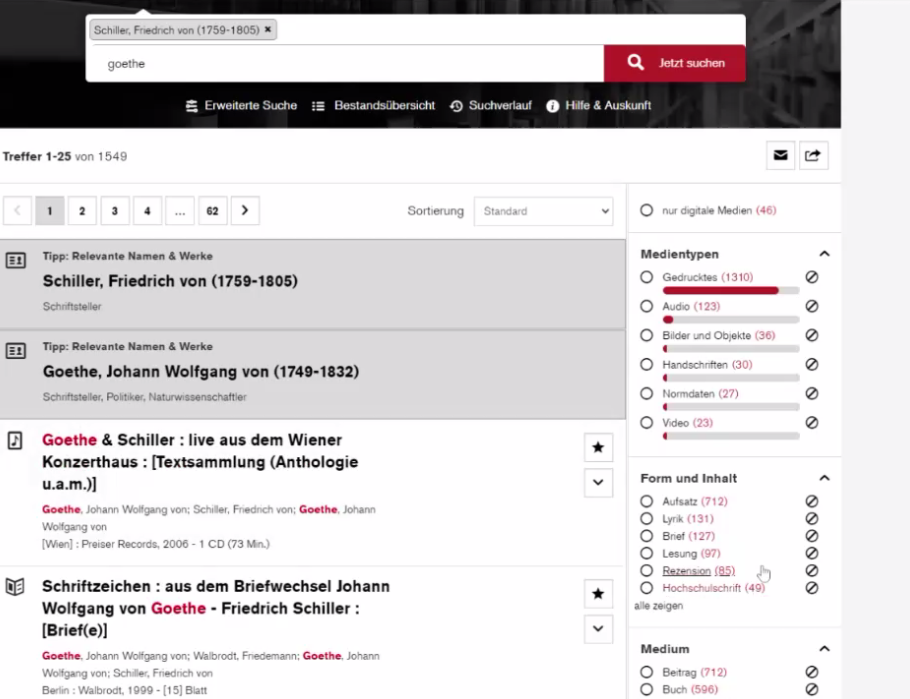
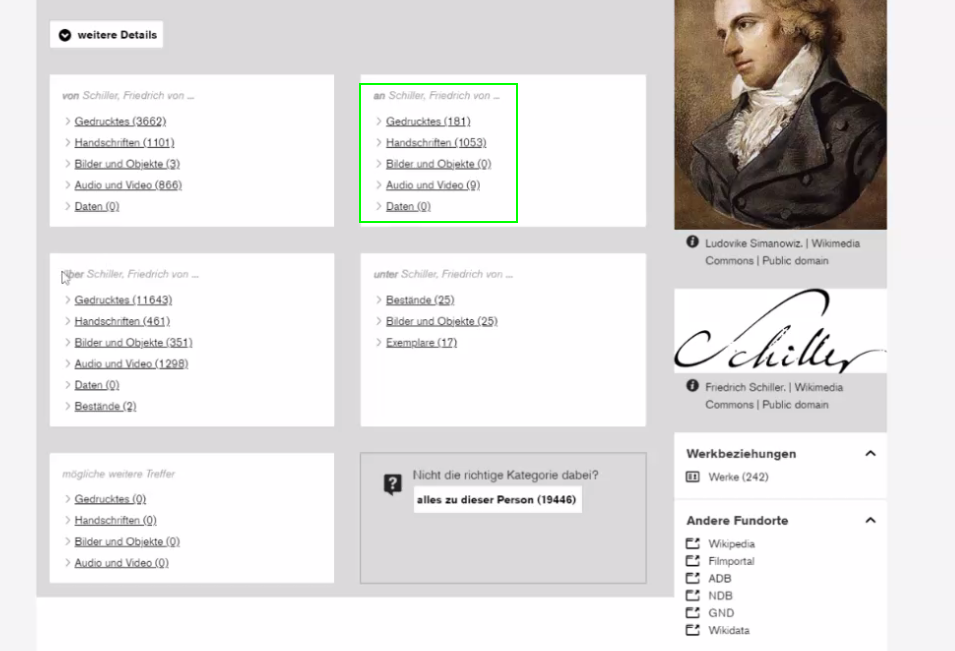
Technikdetails: Solr (Autovervollständigung mit Filter auf Normdaten: alle Ressourcen durch die Normdaten verknüpft) mit Typo3Find als Suchoberfläche, da nicht MARC21-Format, sondern eigenes Schema (über 500 verschiedene Felder), weswegen ein generisches System besser ist. Dazu wurde ein eigenes Metadatenschema entworfen (einfaches .csv-Format). 4 Mio. Datensätze werden jede Nacht mit OpenRefine aus den Katalogen abgefragt (da inkrementell nicht möglich) und einmal die Woche über Wikidata und lobid angereichert.
Entstanden ist mit eigentlich klassischen textbasierten Filtern ein Quasi-Linked-Data-Katalog, es gibt aber auch eine tektonische Darstellung mit Bestandsübersicht für Archivbestände.
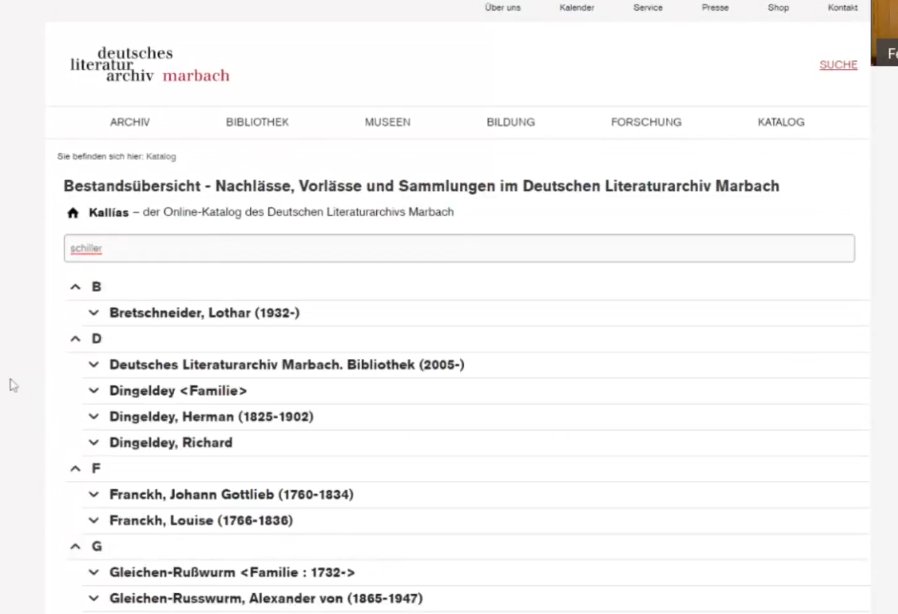
Dauer des Projekts inklusive einjährigem Vorprojekt: vier Jahre. Das ganze wird wohl ab erstem Quartal nächstes Jahr online sein. Gratulation! Das sieht sehr vielversprechend aus!
-
zu RiC und RiC-O gibt es für interessierte eine aktuelle Präsentation von Florence Clavaud. ↩
-
An dieser Stelle kann ich nicht umhin, noch etwas Werbung zu machen für das nette kleine Lernvideo, das wir im letzten Semester als Gruppenarbeit im Modul DPMS erstellt haben und das das Zusammenspiel von MARC, FRBR und RDA erklärt, was zumindest für FRBR in diesem Zusammenhang gut reinpasst. Katharina kapiert Katalogisieren. Wenn es gefällt, gern im Kurs verwenden. ↩